[NLP] MLLM(多模態LLM) 論文簡要欣賞
Abstract & Overview
這篇文章我們來欣賞一下在arXiv上的一篇論文:
A Servey on Multimodal Large Language Models
這篇論文主要在介紹與整理現行代表性的MLLM(Multimodal LLM),並將其分類為4大體裁:
Multimodal Instruction Tuning(M-IT), Multimodal In-Context Learning(M-ICL), Multimodal Chain-of_Thought(M-CoT)以及LLM-Aided Visual Reasoning(LAVR)。
其中,前三者為MLLM的基礎,而最後一個則是以LLM為核心的multimodal system,類似於一個系統框架。
MLLM指的是在LLM的基礎上,從單模態走向多模態,從人工智慧的角度來看,MLLM比LLM向前又跨出了一步,原因如下:
- MLLM更符合人的感官世界,自然地接受多感官輸入
- MLLM提供一個友好的介面,支持多模態輸入,使其易於與使用者交流
- MLLM是一個更全面的問題解決者,雖然LLM可以解決NLP的問題,但MLLM通常可以支持更大範圍的任務
下面我將針對這篇論文中較為重要的部分做簡要的欣賞與分析 ,其他細節部分可以自行閱讀這篇精彩的論文!
Prerequest & Note
在開始之前,先介紹在論文中常出現的一些基本名詞
IT, ICL, CoT
讓我們先看一下這三者的定義:
- Instruction Tuning:
- Instruction tuning involves fine-tuning a pre-trained language model by providing specific instructions during the training process.
- These instructions can be in the form of prompts or demonstrations, guiding the model to generate responses in a desired manner.
- It allows for controlled language generation and can be useful for generating responses tailored to specific tasks or contexts.
- In Context Learning:
- In context learning refers to training a language model on a large dataset with diverse contexts and topics.
- The model learns to understand and generate responses based on the context it is given, which allows for more contextually relevant and coherent responses.
- This approach is suitable for applications where the model needs to understand and adapt to various contexts during language generation.
- Chain of Thought:
- Chain of thought is a concept in natural language generation where the model maintains coherence throughout a conversation by remembering past interactions.
- The model keeps track of the conversation history, ensuring consistent responses and avoiding contradictions.
- This is especially valuable in chatbot applications to provide more human-like and coherent conversations.
簡單整理一下三者的差異:
- Instruction Tuning 著重於微調模型以遵循特定的指令或指導,使其更好地符合特定任務或需求的生成。
- In-Context Learning 強調理解上下文,確保生成的結果與上下文相關且連貫。
- Chain-of-Thought 強調模型生成文本時的連貫性,能夠記住過去的互動,使生成的文本像人類思維的連貫性一樣。
這三個方法或概念是獨立的,但可以搭配使用,創造更好的效果。
Zero-Shot, Few-Shot Learning
先看一下兩者的定義:
Zero-Shot Learning:
- Zero-shot learning is a learning paradigm where a model is trained to perform a task for which it has never seen any examples during training.
- In other words, the model is expected to generalize its knowledge from the training data to new, unseen categories or tasks.
Few-Shot Learning:
- Few-shot learning is a similar concept, but it allows a model to be trained on a very small number of examples for each new category or task it encounters. *
- Instead of needing a large amount of data per class, few-shot learning aims to generalize from a few examples.
- It’s like teaching a model to learn from just a handful of samples. This is particularly useful in scenarios where collecting a substantial amount of data for each new class is impractical.
Note
這邊整理了一些重要的專有名詞
- Learning Paradigm
- A learning paradigm refers to a specific approach or framework used to train machine learning models.
- It encompasses the fundamental principles, methods, and strategies that guide how models are constructed, trained, and evaluated.
- Different learning paradigms offer distinct ways of addressing various types of problems and data.
- E.g. Supervised Learning, Semi-Supervised Learning, Reinforcement Learning, Transfer Learning, etc.
簡單整理一下兩者的差異:
- Zero-Shot Learning 利用先前學習的知識,執行全新、未看過的任務類別。
- Few-Shot Learning 利用少量的範例(有答案),去適應新的任務類別。
M-IT
Instruction指的是對於任務的描述,IT是一種利用instruction-formatted datasets來訓練LLM的技巧。利用這個技巧,LLM可以透過跟隨新的instruction來泛化未曾看過的新任務,進而實現zero-shot learning的成效。
下面是論文中引用來描繪instruction tuning與其他learning paradigms的圖示
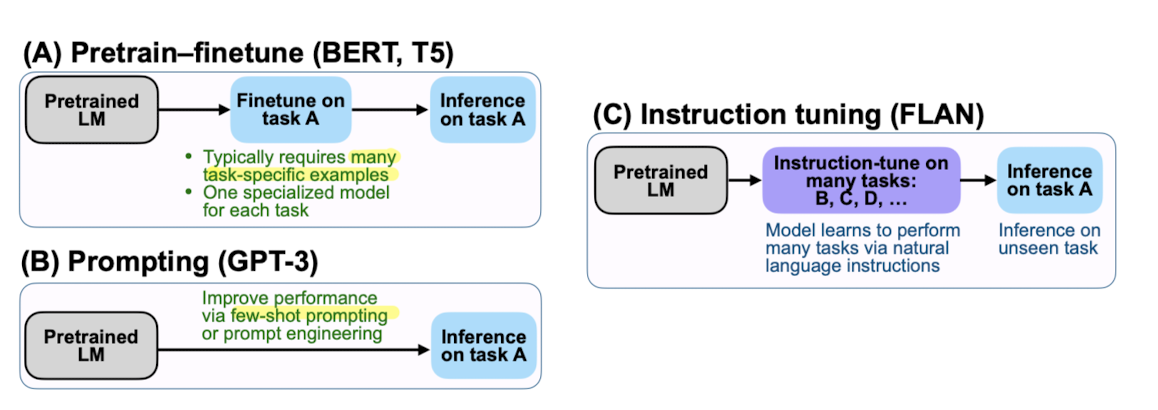
為了要從unimodality到mutimodality,需要調整的部分主要 分為兩個:”Data” 和 “Model”。
在Data方面,我們常 調整現存的benchmark datasets來取得M-IT datasets,或是使用self-instruction。
下面的圖簡單呈現了M-IT data的模板![]()
在Model方面,一個常見的做法是將 其他modalities的資訊注入進LLM,並把LLM當成是一個強大的推理者。 其他相關的著作常會直接將理解外來modality的能力嵌入進LLM;或是使用expert model把外來的modality轉換成LLM可以理解的natural language。

Formulation M-IT & M-IT sample
這邊我簡單把論文中提到有關M-IT以及其目標函數的內容拉出來
M-IT sample其實可以被標示為三元素的數組:
$$(I, M, R)$$
分別代表instruction, multimodal input以及ground-truth response
MLLM利用給予的instruction和multimodal input預測answer
$$ A = f(I, M; \theta)$$
其中,A代表預測的答案(answer),$\theta$ 則代表模型中的parameters
而訓練的目標是要最小化loss function,而MLLM的目標是要預測下一個response的token,基於這點,loss function可以這麼表示:
$$\begin{equation}
L(\theta) = -\sum_{i=1}^N\log{}p(R_i|I,R_{<i};\theta)
\end{equation}$$
其中,
- N為ground-truth response的長度
- 使用log是因為將機率連乘轉為連加,以避免underflow
- 因為是loss function,所以加個負號,最小化loss function同時最大化預測下個token的機率
- 利用instruction與前i-1個ground truth response token預測第i個token
Bridgin the gap between different modalities
在這篇論文中提到一個非常重要的問題:該怎麼連結不同的modalities?
主要有兩種方法:
- Learnable Interface:
- 在LLM的其中一個模組或權重下去做調整,並插入在pre-trained visual encoder與LLM之間,作為一個可以用來訓練模態轉換的model。
- 連結不同的modalities的同時,凍結pre-trained model的parameters。
- 如何將視覺內容轉為LLM可以理解得文字格式
- Expert model:
- 利用其他模型,轉換外來的modality成不需要訓練訓練的語言,例如image captioning model(不用訓練)。
- 可能不像learnable interface那樣彈性,且有information loss的風險
M-ICL
先介紹兩個ICL的特點:
- supervised learning是從大量的資料中學習資料背後的模式,與傳統supervised learning不同的是,ICL的關鍵是”類推”,從少量的資料搭配一些選填的instruction,去外推新的問題與任務,因此使用few-shot learning的方式解決全新的問題。
- ICL常常使用training-free的方式實作,因此可以在inference stage,很容易地整合進不同的框架。
- IT與ICL十分相關,IT常常被拿來加強模型的ICL能力。
下面的圖示描繪了簡化過後的M-ICL query模板,其中,使用了兩個in-context範例和一個query,兩者用虛線隔開,模型的目的是要完成這個request。
M-CoT
CoT is “a series of intermediate reasoning steps”, which has been proven to be effective in complex reasoning tasks.
- CoT主要是想讓我們在prompt LLMs時,讓他生成不只是最後的答案,而是要有推理的過程而引導到最終解答。
- 在M-CoT中有幾個重要的概念:modality bridging(解決modality gap), learning paradigms, chain configuration以及generation patterns。
Modality Bridging
- 使用Learnable Interface:
- 這個方法使用一個learnable interface把visual embedding mapping到word embedding空間。
- 這個mapped embedding可以被視為是一個prompt,進而傳遞給LLMs,引出其M-CoT的能力
- 舉例來說,CoT-PT使用多個Meta-Net來作prompt tuning,Meta-Net將visual features轉換成階段性的prompt,其中,可以把Meta-Net想像為CoT-PT的其中一個模組。
- Multimodal-CoT使用shared Transformer-based 架構,visual與textual特徵通過cross-attention進行交互。
- 使用Expert Model:
- 引用expert models來將visual input翻譯為texual description
- 儘管其非常直接且簡單,但在轉換的過程中可能會遇到information loss的問題
Learning Paradigms
learning paradigms也可以解釋為模型如何從資訊中獲取知識。大致可以分為 三種方式來習得M-CoT的能力
- fintuning:
通常需要針對M-CoT的datasets - training-free few-shot learning:
同常需要手作一些in-context的範例讓模型去學如何推理 - training-free zero-shot learning:
直接prompt就可以,不需要其他明顯的指引,舉例來說”Let’s think frame by frame”
其中對於sample size的要求由上而下遞減
Chain Configuration
簡單來說就是要什麼時後該停止推裡,主要有adaptive和pre-defined formation兩種方法。
- Adaptive:
要求LLMs自己決定何時該停止reasoing chains - Pre-defined formation
使用者事先設定好reasoning chains的長度
Generation Pattern
Reasoning chain是如何建構的?
主要有兩種可能
- Infilling-based pattern:
需要在上下文中去做演繹(前幾步與後幾步),去填補邏輯漏洞 - predicting-based pattern:
利用已知的條件、instruction以及過去推理的資訊去擴充reasoning chain
不管是哪種模式,都必須要求生成的文本必須是連續且正確的
LAVR
將LLMs作為helpers,以及其他不同的角色,建構出一個支持特定任務或genral-purpose的visual reasoning system
跟傳統的visual reasoning system相比,LAVR有一些更好的特點:
- Strong generalization ability:
擁有眾多知識並以大量資料及訓練的模型,可以容易地泛化未看過的任務,並在zero-shot/few-shot擁有不錯的性能。 - Emergent abilities:
其定義為,在小的模型不會出現,而在大模型會出現的能力,當模型到一定的scale會湧現的能力,例如能夠看到圖片表面下的意義,像是能夠理解會和一個迷因是好笑的。 - Better interactvity and control:
LLM-based system提供一個更好使用與控制的使用者介面,例如使用自然語言的query進行互動。
下面我將介紹論文中提到的,LAVR不同的training paradigm以及LLM在這個系統中扮演的角色
Training Paradigms
主要有兩種:
- training-free:
- few-shot models:
需要少量的hand-crafted in-context sample,去指引LLMs產生程式或一連串的執行步驟, 這些程式或執行步驟是作為其他對應模型或外部工具與模組的instructions - zero-shot models:
依賴LLMs的語言相關知識與推理能力,例如CAT使用LLMs去refine影像的caption,使其更符合使用者的需求
- few-shot models:
- finetuning:
主要是想要激活LLMs在LAVR中的planning abilities(對應到工具的使用),以及instruction-following abilities。
Functions
LLMs在LAVR system中扮演的主要角色,主要有三種
- LLM as a Controller
- LLM as a Decision Maker
- LLM as a Semantics Refiner
前兩者(controller & decision maker)與CoT相關,因為複雜的任務需要被拆解為intermediate simpler tasks。
當LLMs作為controller時,任務常常是在single round完成的,而multi-round更常見於decision maker
LLM as a Controller
- Break down a complex task into simpler sub-tasks
常運用LLMs的CoT能力 - Assigns these tasks to appropriate tools/modules
LLM as a Decision Maker
在這個case中,複雜的任務會以multi-round的方式被解決,decision maker通常要滿足以下能力
- 總結目前的上下文以及歷史資訊,並判斷目前的資訊是否足夠推導出最終解答
- 整理並總結答案,並且用user-friendly的方式呈現給使用者
LLM as a Semantics Refiner
使用LLMs豐富的語言與語義知識,去對最終解答做加強
Conclusion
這篇論文整理的現行MLLM的資訊,並給出了主要的幾個方向,包括包括3個常見的技巧(M-IT, M-ICL, M-CoT),和一個task-solving systems的廣泛框架(LAVR)。
論文中還有許多evaluation的方式,以及現在研究需要被填充的gap,其他更詳細的內容還有待讀者親自去欣賞這篇論文!
References
- https://arxiv.org/abs/2306.13549
- https://zhuanlan.zhihu.com/p/639664615