[NLP][ML] Adapters & LoRA
Overview
In this article, I will provide an introduction to adapters and LoRA, including their definitions, purposes, and functions. I will also explore their various applications and, lastly, delve into the distinctions that set them apart(the differences between them).
Adapter
What are Adapters?
According to this article
We can give the definition of adapters:
Adapters are lightweight alternatives to fully fine-tuned pre-trained models.
Currently, adapters are implemented as small feedforward neural networks that are inserted between layers of a pre-trained model.
They provide a parameter-efficient, computationally efficient, and modular approach to transfer learning. The following image shows added adapter.
The image below clearly shows the usage flow of apadters
(Source: AdapterHub)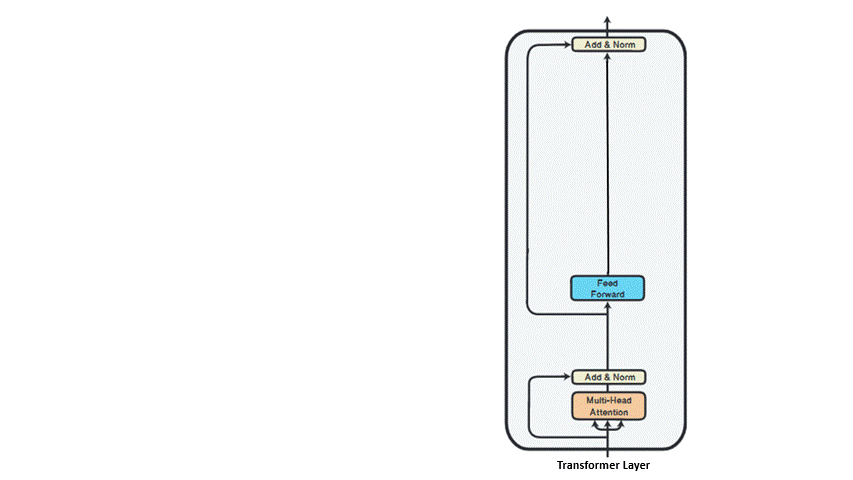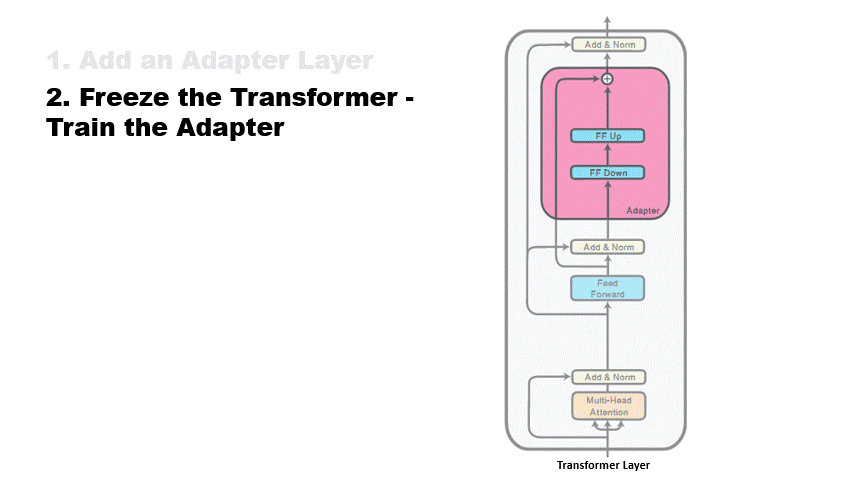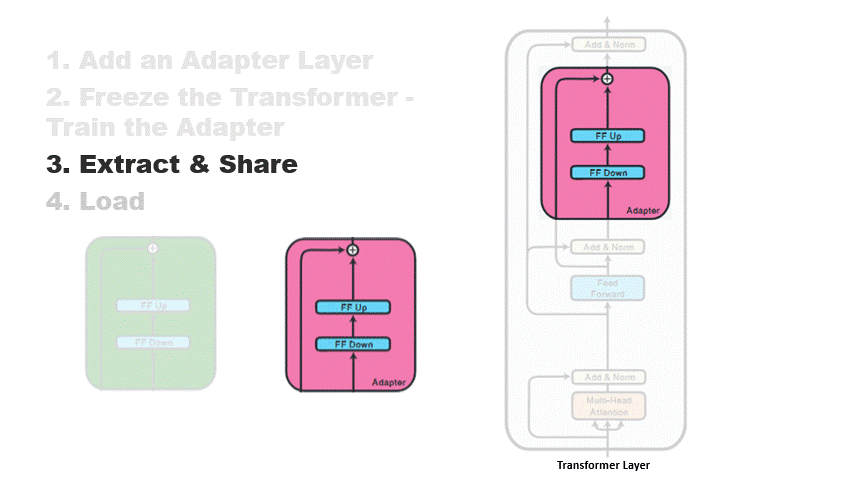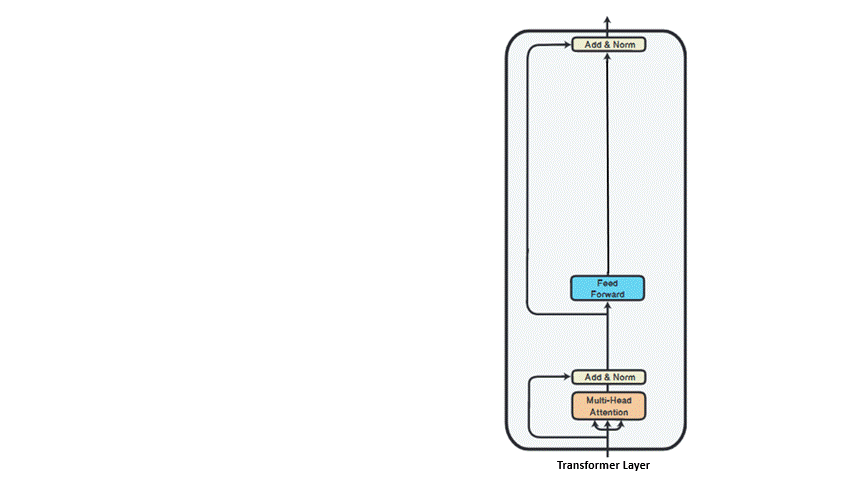
During training, all the weights of the pre-trained model are frozen such that only the adapter weights
are updated, resulting in modular knowledge representations. They can be easily extracted, interchanged,
independently distributed, and dynamically plugged into a language model. These properties highlight the
potential of adapters in advancing the NLP field astronomically.
What is the purpose and function of adapters?
- Purpose:
Large Language Models are computationally expensive and memory-intensive. Fine-tuning the entire model for each specific task can be impractical due to resource constraints. Adapters provide a solution by allowing for more efficient and targeted modifications to the model for different tasks. This approach saves both computational power and memory, enabling the deployment of a single pre-trained model for multiple tasks. - Functions:
Efficient Fine-tuning: Instead of fine-tuning the entire model, adapters enable fine-tuning only a small subset of parameters related to a specific task. This fine-tuning process is faster and requires fewer resources.
Task-specific Modifications: Adapters allow you to add task-specific layers or modifications to the pre-trained model without altering the core architecture. This makes it easier to adapt the model for various tasks like text classification, named entity recognition, sentiment analysis, etc.
Versatility: With adapters, a single pre-trained LLM can be adapted for a wide range of tasks. This versatility is beneficial in scenarios where deploying and maintaining separate models for each task might be impractical.
Interoperability: Adapters enable the combination of pre-trained models with task-specific modifications in a standardized way. This facilitates sharing, collaboration, and research in the NLP community.
Transfer Learning: Adapters enhance the effectiveness of transfer learning. Models pre-trained on large and diverse datasets can be fine-tuned on smaller, task-specific datasets using adapters, improving performance on specific tasks.
Incremental Updates: Adapters allow for easy updates to the model. Instead of retraining the entire model, only the adapters related to a specific task need to be fine-tuned when new data or requirements arise.
Overall, adapters are a mechanism that strikes a balance between the benefits of fine-tuning for specific tasks and the efficiency of reusing pre-trained LLMs. They enable the NLP community to leverage the power of these large models while tailoring them to a diverse set of applications.
The applications of adapters
I list some practical applications that can use adapters to enhance.
Efficient Task Adaptation: Adapters make it possible to fine-tune a pretrained model for specific tasks with minimal computational resources and time. This is particularly useful for industries that require quick adaptation to changing trends or requirements.
Multilingual Applications: Adapters can be used to enable a pretrained model to perform tasks in multiple languages. This is valuable for businesses operating in global markets.
Domain-Specific NLP: Adapting models with domain-specific adapters (e.g., medical, legal, financial) enhances their performance on tasks specific to those domains.
Personalization: Adapters can be used to personalize a general-purpose model for individual users or contexts, leading to more relevant and tailored responses.
LoRA (Low-Rank Adaptation)
What is LoRA?
- Low-Rank Adaptation, or LoRA, is proposed, which freezes the pre-trained model weights and injects trainable rank decomposition matrices into each layer of the Transformer architecture, greatly reducing the number of trainable parameters for downstream tasks.
And let’s see the full fine-tuning definition:
- Full fine-tuning LLM, which retrains all model parameters, becomes less feasible. Using GPT-3 175B as an example — deploying independent instances of fine-tuned models, each with 175B parameters, is prohibitively expensive.
In this article, it clearly compare the fine-tuning and LoRA approaches. And in this article, it dives more into the machanism of LoRA. If you wnat to know the full knowledge, you can refer to the paper of LoRA.
In the next sections, I will introduce more ideas of LoRA based on these references. Note that I only organize the contents of these articles and add some mark and note on my own.
How does fine-tuning LLMs work?
Open-source LLMs such as LLaMA,Vicuna are foundation models that have been pre-trained on hundreds of billions of words. Developers and machine learning engineers can download the model with the pre-trained weights and fine-tune it for downstream tasks such as instruction following.
The model is provided input from the fine-tuning dataset. It then predicts the next tokens and compares its output with the ground truth. It then adjusts the weights(gradient) to correct its predictions. By doing this over and over, the LLM becomes fine-tuned to the downstream task.
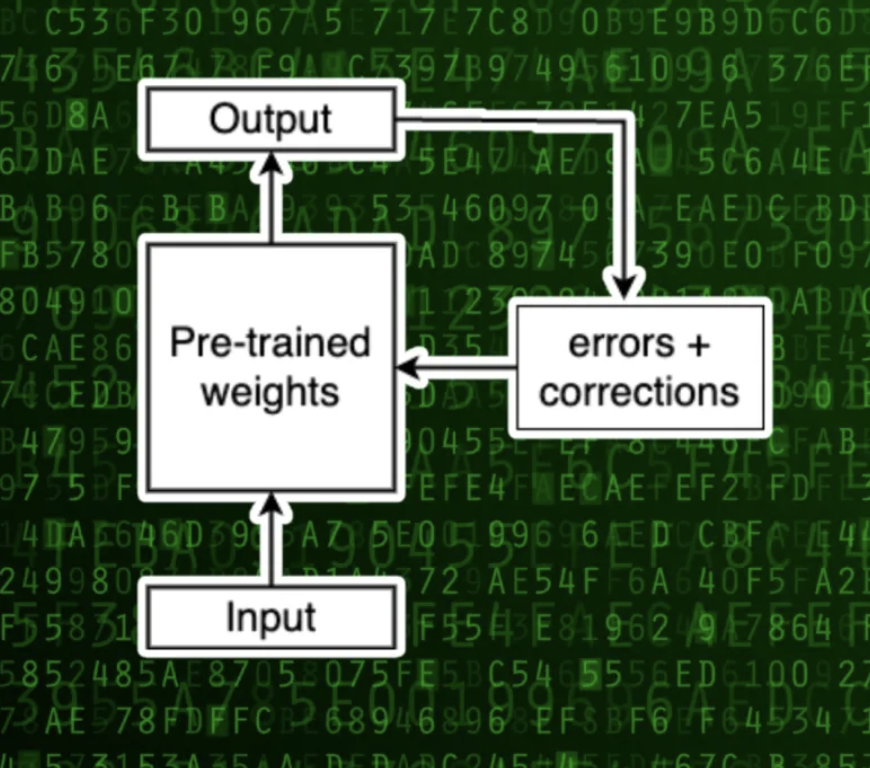
(Source: What is low-rank adaptation (LoRA)?)
The idea of LoRA
Now, let’s make a small modification to the fine-tuning process. In this new method, we freeze the original weights of the model and don’t modify them during the fine-tuning process. Instead, we apply the modifications to a separate set of weights and we add their new values to the original parameters. Let’s call these two sets “pre-trained” and “fine-tuned” weights.
Separating the pre-trained and fine-tuned parameters is an important part of LoRA.
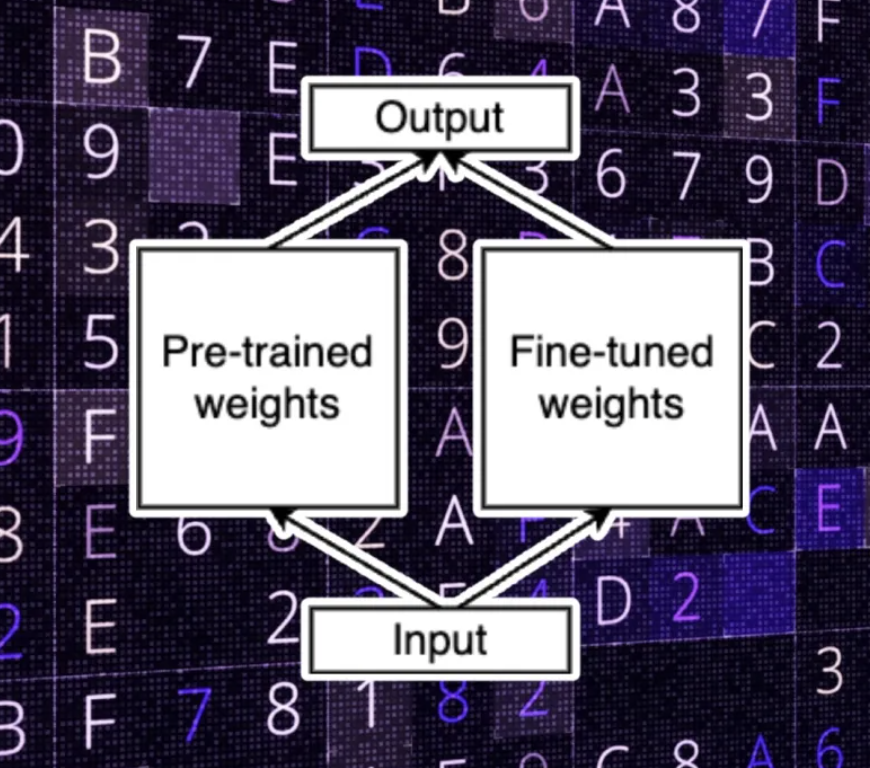
Low-rank adaptation
Before moving on to LoRA, let’s think about our model parameters as very large matrices. If you remember your linear algebra class, matrices can form vector spaces. In this case, we’re talking about a very large vector space with many dimensions that models language.
Every matrix has a “rank”, which is the number of linearly independent columns it has. If a column is linearly independent, it means that it can’t be represented as a combination of other columns in the matrix. On the other hand, a dependent column is one that can be represented as a combination of one or more columns in the same matrix. You can remove dependent columns from a matrix without losing information.
LoRA, proposed in a paper by researchers at Microsoft, suggests that when fine-tuning an LLM for a downstream task, you don’t need the full-rank weight matrix. They proposed that you could preserve most of the learning capacity of the model while reducing the dimension of the downstream parameters. (This is why it makes sense to separate the pre-trained and fine-tuned weights.)
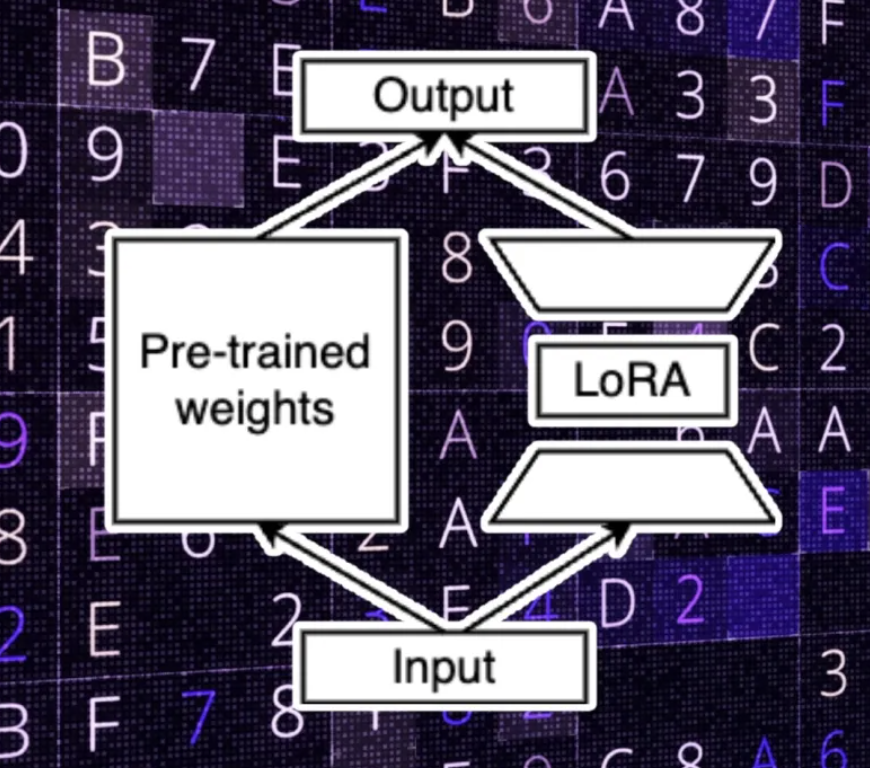
Basically, in LoRA, you create two downstream weight matrices. One transforms the input parameters from the original dimension to the low-rank dimension. And the second matrix transforms the low-rank data to the output dimensions of the original model.
During training, modifications are made to the LoRA parameters, which are now much fewer than the original weights. This is why they can be trained much faster and at a fraction of the cost of doing full fine-tuning. At inference time, the output of LoRA is added to the pre-trained parameters to calculate the final values.
More detail
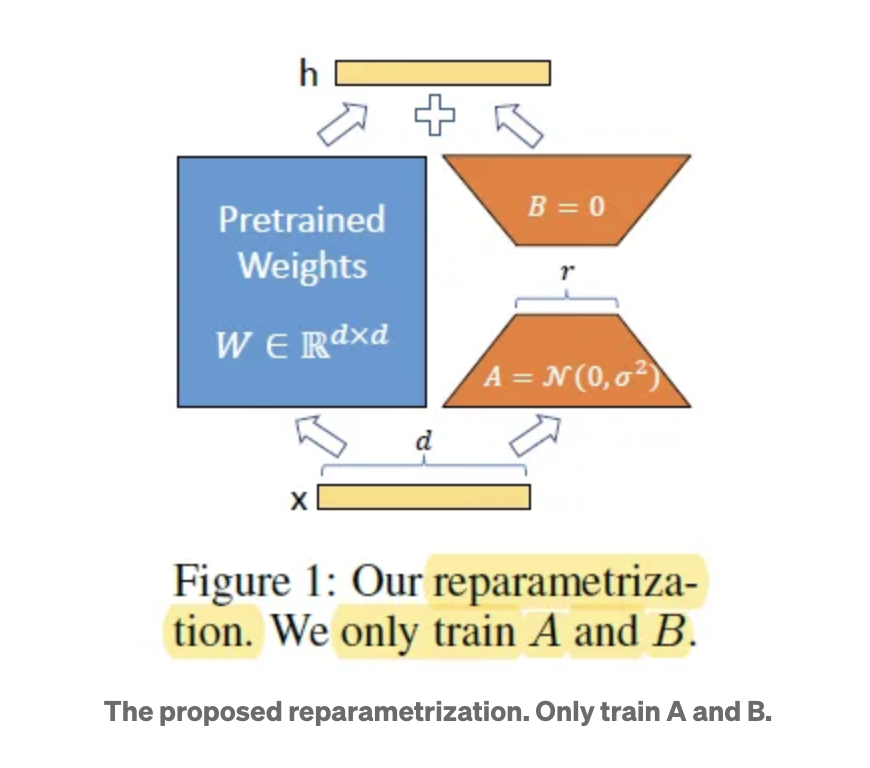
- For a pre-trained weight matrix $W_0$, its update is constrained by representing the latter with a low-rank decomposition:
$$\begin{equation}
W_0 + \Delta{W} = W_0 + BA
\end{equation}$$
- During training, $W_0$ is frozen and does not receive gradient updates, while A and B contain trainable parameters.
- For $h=W_0$, the modified forward pass yields:
$$\begin{equation}
h = W_0x + \Delta{W}x = W_0x + BAx
\end{equation}$$
A random Gaussian initialization is used for A and zero is used for B, so $\Delta{W}=BA$ is zero at the beginning of training. (The method of initializing the weights)
One of the advantages is that when deployed in production, we can explicitly compute and store $W=W_0+BA$ and perform inference as usual. No additional latency compared to other methods, such as appending more layers.
You can see the implementation and more detail of LoRA in this video
and this article.
What is the purpose and function of LoRA?
- Purpose
- The purpose of LoRA is to make it easier and more efficient to fine-tune LLMs for downstream tasks.
- Function
- The function of LoRA is to decompose the LLM into a low-rank representation and then adapt this representation to the target task.
- Here are the benefits:
- Reduced number of parameters: The low-rank representation has a much smaller number of parameters than the original LLM, which can make it faster to train and easier to deploy.
- Improved performance: The low-rank representation is able to capture the most important features of the LLM, which can lead to improved performance on the downstream task.
The applications of LoRA
- Fine-tuning large language models for downstream tasks:
LoRA can be used to fine-tune large language models (LLMs) for a variety of downstream tasks, such as question answering, summarization, and translation. This can make LLMs more accessible and easier to use for a wider range of applications. - Improving the efficiency of machine learning models:
LoRA can be used to improve the efficiency of machine learning models by reducing the number of parameters. This can make models faster to train and easier to deploy. - Compressing large datasets:
LoRA can be used to compress large datasets by representing them in a low-rank format. This can make datasets easier to store and transmit. - Improving the security of machine learning models:
LoRA can be used to improve the security of machine learning models by making them more resistant to adversarial attacks.
Differences between adapter and LoRA
| Feature | Adapter | LoRA |
|---|---|---|
| Approach | Adds additional layers to the pretrained model | Decomposes the pretrained model into a low-rank representation |
| Parameters | Adds a small number of parameters to the pretrained model | Reduces the number of parameters in the pretrained model |
| Performance | Effective for a variety of downstream tasks | Particularly effective for tasks that require a large number of parameters |
| Speed | Can be faster to train than LoRA | Can be faster at inference time |
| Memory usage | Can use more memory than LoRA |
In general, adapters are a good choice for tasks that require a small number of parameters and can be trained quickly, while LoRA is a good choice for tasks that require a large number of parameters and need to be fast at inference time.
References
- (Recommend) Training an Adapter for RoBERTa Model for Sequence Classification Task
- AdapterHub
- Low-Rank Adaptation of Large Language Models (LoRA) (Huggingface)
- Brief Review — LoRA: Low-Rank Adaptation of Large Language Models
- What is low-rank adaptation (LoRA)?
- LoRA: Low-Rank Adaptation of Large Language Models (Paper)
- (Recommend) Low Rank Adaptation: A Technical Deep Dive
- Low-rank Adaption of Large Language Models: Explaining the Key Concepts Behind LoRA (Video)
- Fine-tuning LLMs with PEFT and LoRA
- PEFT: Parameter-Efficient Fine-Tuning of Billion-Scale Models on Low-Resource Hardware