[AWS-CPE] Database and Storage
Introduction
Storage refers to the preservation of digital data in a form that can be accessed by a computer system. It comes in various types, such as hard drives, solid-state drives, USB flash drives, and cloud storage. These storage devices can hold data temporarily or permanently.
Databases, on the other hand, are structured systems for organizing, storing, and retrieving data. They allow for efficient data management and can handle large amounts of information systematically. Databases can be relational, where data is stored in tables and relationships can be defined between these tables, or non-relational (NoSQL), which are more flexible and can store unstructured data. The management of databases is handled through database management systems (DBMS), which provide tools for creating, querying, updating, and administering the database.
Outline
In this article, we will talk about the database and storage service in AWS. This article is based on the courses on the AWS SkillBuilder platform. (Module5)
- Summarize the basic concept of storage and databases.
- Describe the benefits of Amazon Elastic Block Store (Amazon EBS).
- Describe the benefits of Amazon Simple Storage Service (Amazon S3).
- Describe the benefits of Amazon Elastic File System (Amazon EFS).
- Summarize various storage solutions.
- Describe the benefits of Amazon Relational Database Service (Amazon RDS).
- Describe the benefits of Amazon DynamoDB.
- Summarize various database services.
Amazon EBS (Instance Stores and Amazon Elastic Block Store)
Instance Stores provide
temporary block-level storage for Amazon EC2 (Elastic Compute Cloud) instances. This storage is physically attached to the host machine where the instance runs, offering high performance and low latency. However, data on instance stores is ephemeral; it persists only as long as the instance is running and is lost if the instance is stopped, terminated, or if the underlying physical drive fails.
Block Store: (changed only by block)
Instance Store: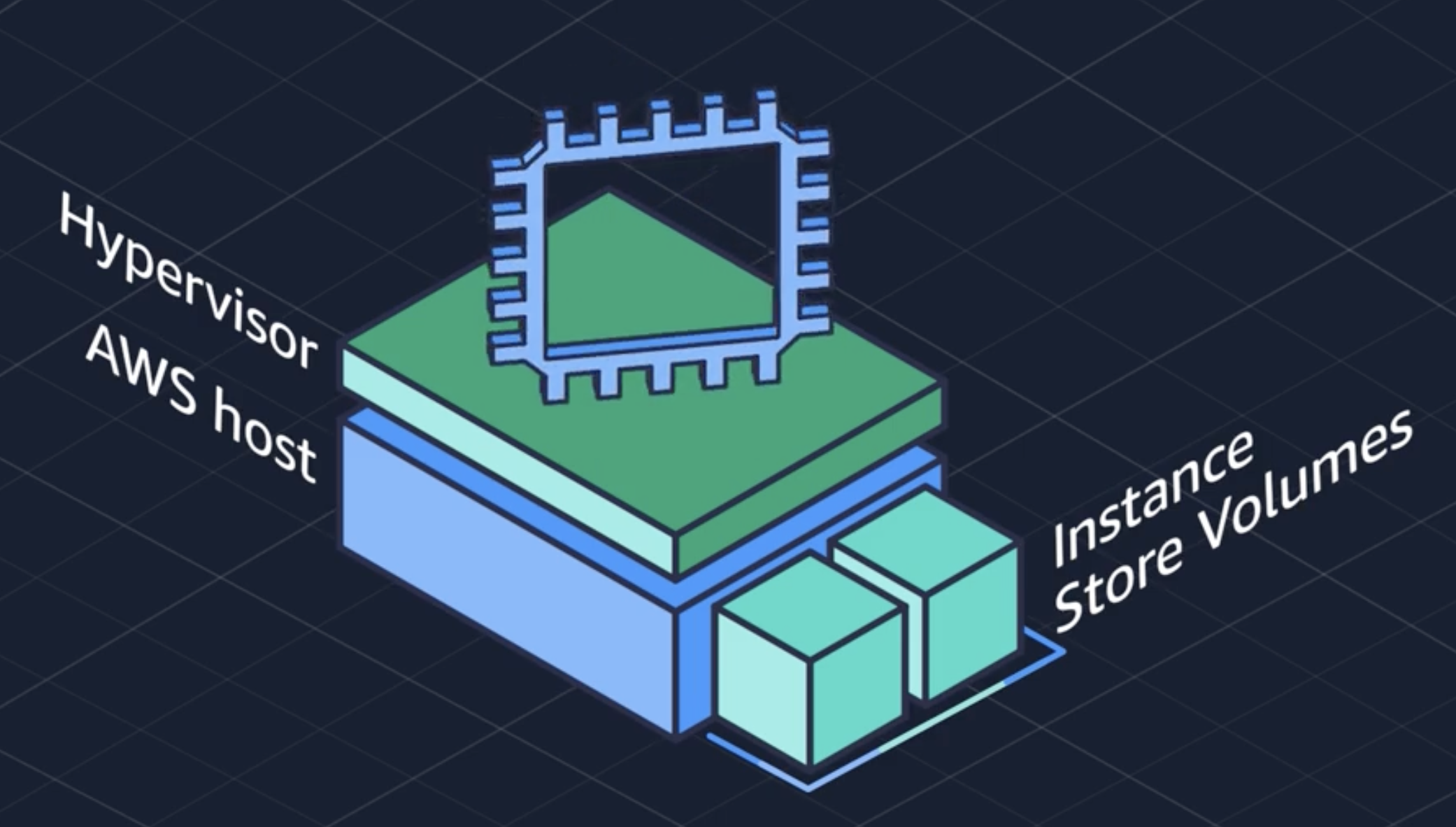
Amazon Elastic Block Store (Amazon EBS)
EBS, in contrast, offers persistent block storage volumes for use with EC2 instances. EBS volumes are network-attached and persist independently of the life of an instance. This means that EBS volumes can be detached from one instance and attached to another, and their data remains intact even after the instance is stopped or terminated. EBS provides various volume types that cater to different use cases, such as high throughput or high IOPS (input/output operations per second), and is designed for both high availability and durability.
EBS Settings:
EBS: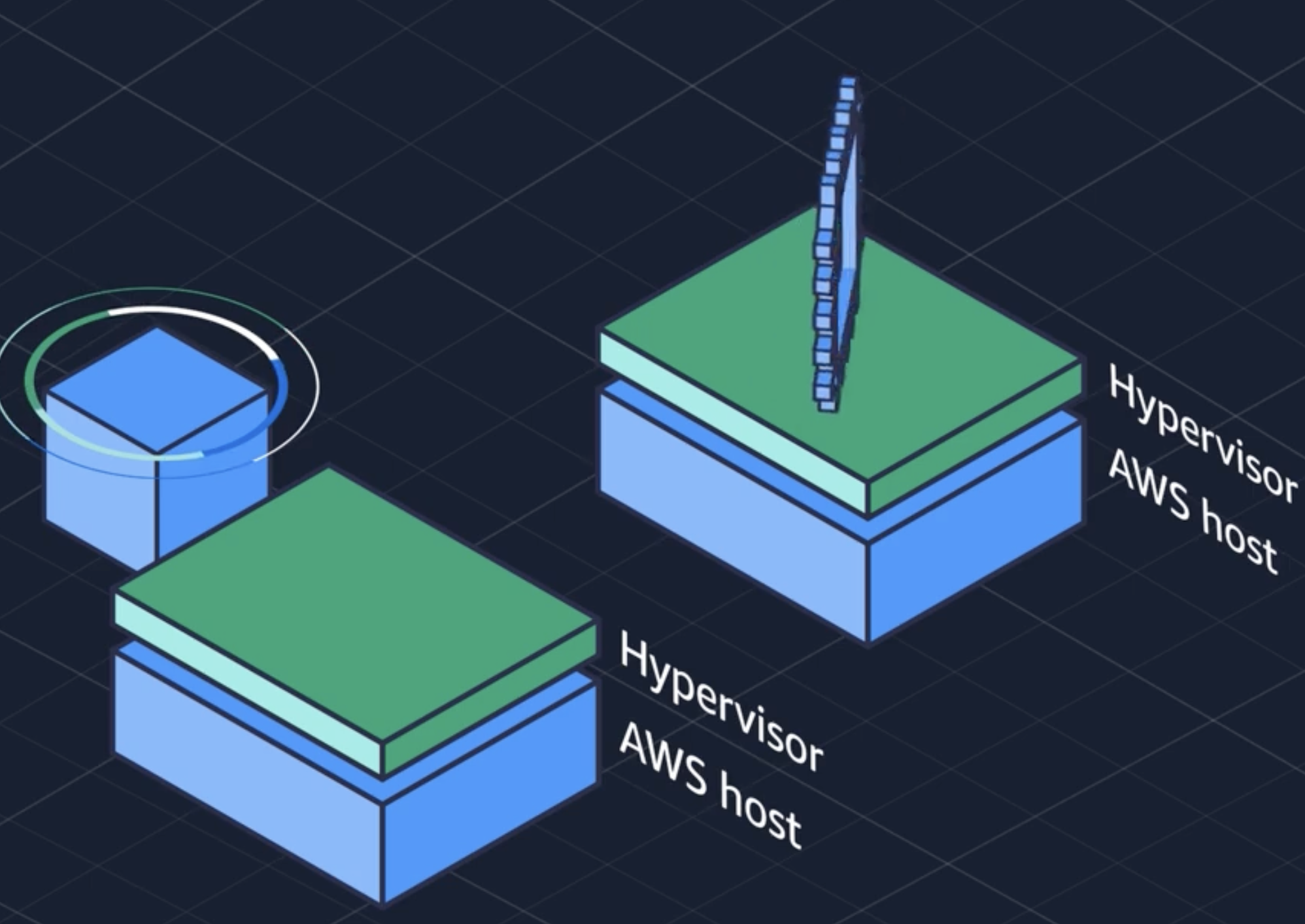
Snapshot
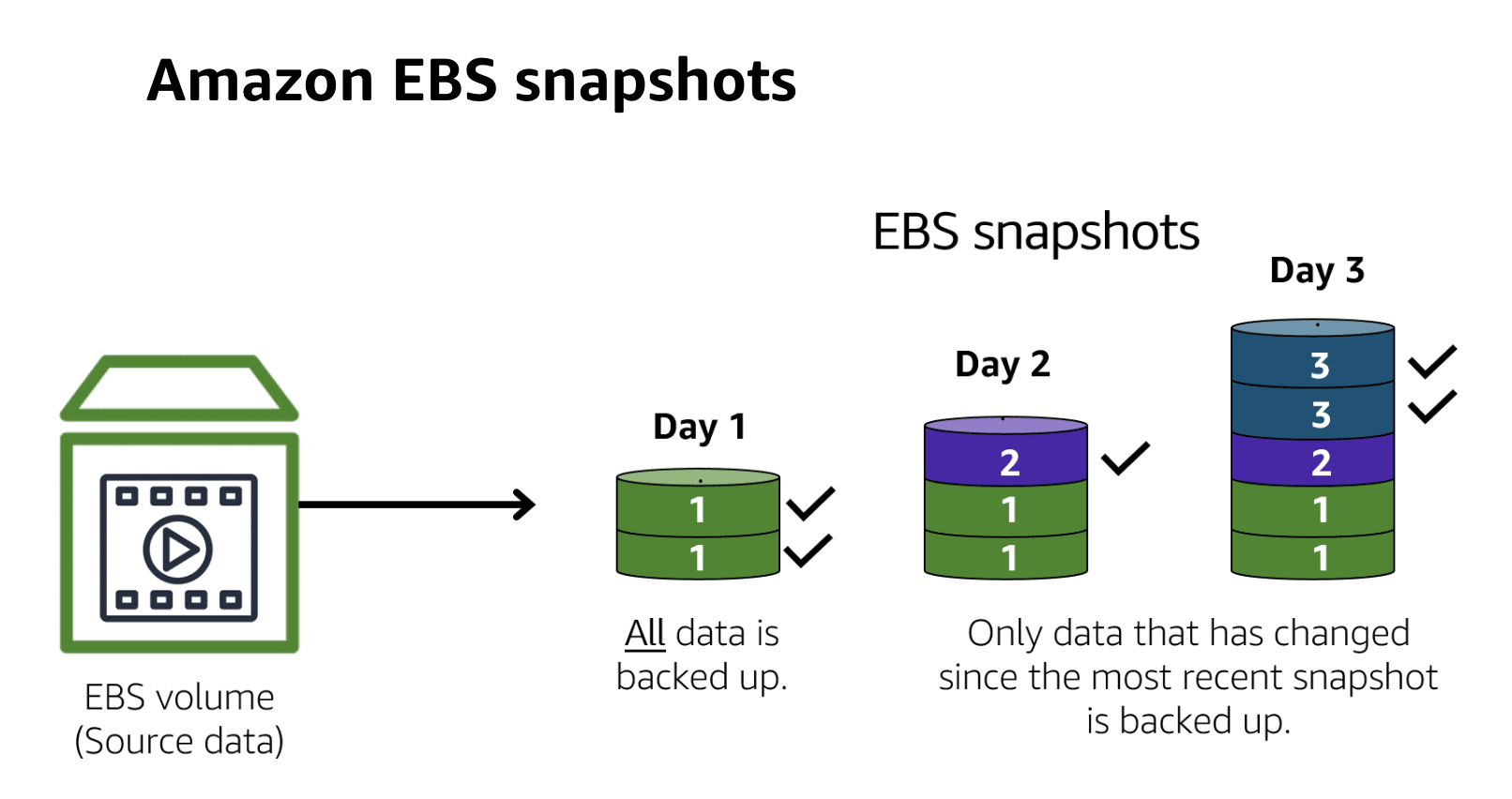
- A snapshot in the context of cloud computing, particularly with Amazon Elastic Block Store (Amazon EBS), is a point-in-time backup of an EBS volume. It captures the exact state of a volume at the time the snapshot is taken and is stored in Amazon S3 (Simple Storage Service) for durability. Snapshots are incremental, meaning only the blocks on the device that have changed after your most recent snapshot are saved, which optimizes both the time required to create the snapshot and the space used on storage.
- Snapshots are widely used for data backup, archiving, and disaster recovery purposes. They can also be used to create new EBS volumes, clone existing volumes, or transfer data across AWS regions. Snapshots are a key feature in ensuring data durability and recoverability in cloud environments.
![]()
Quick Quiz

Amazon S3 (Amazon Simple Storage Service)
Amazon S3 (Simple Storage Service) is a scalable, high-speed, web-based cloud storage service designed for online backup and archiving of data and application programs. S3 provides an object storage format, which differs from traditional file systems or block storage. Data is stored as objects within buckets, and each object consists of the file itself and metadata containing a globally unique identifier and other information. S3 is widely recognized for its durability, availability, and scalability.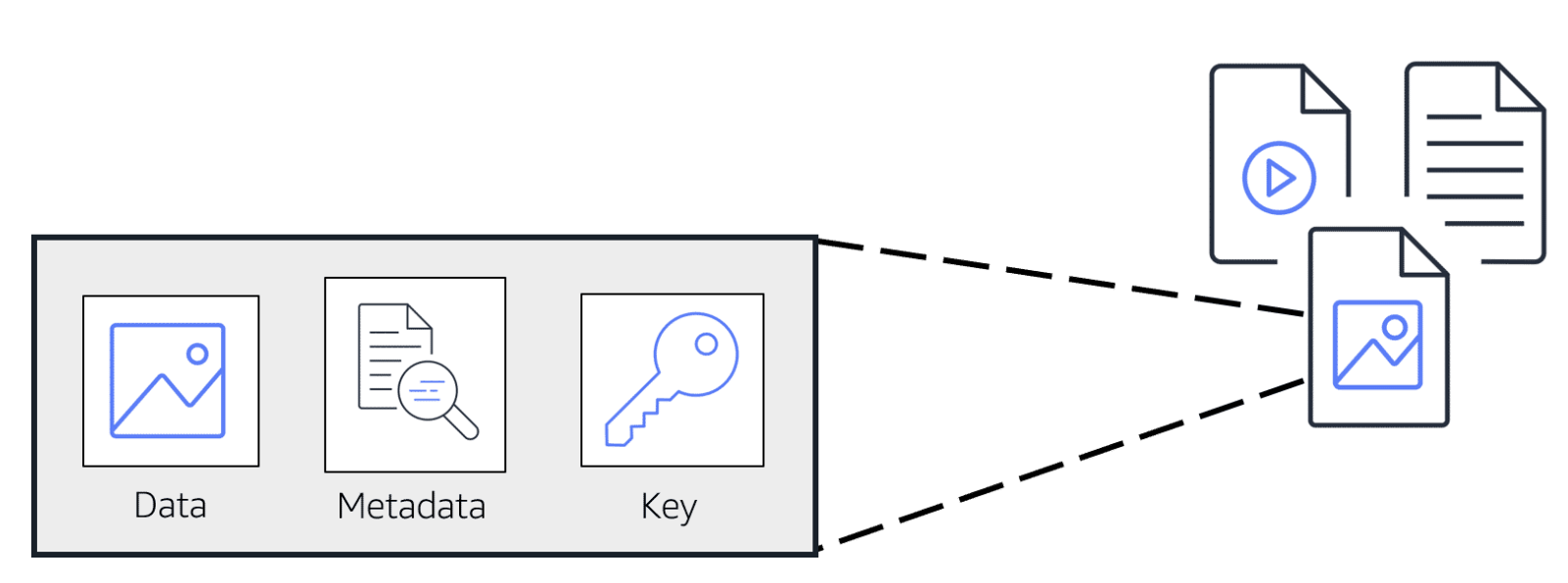
- Key features of S3 include:
- Buckets: Containers for storage of any amount of data at any time. Each bucket is identified by a unique, user-defined name.
- Objects: Files or blobs of data that are stored in buckets. Objects are identified within a bucket by a unique, user-assigned key.
- Scalability: Ability to store and retrieve any amount of data, from small files to large datasets, at any time.
- Data Availability and Durability: Designed for 99.999999999% (11 9’s) of durability, ensuring data protection against losses.
- Security: Supports various mechanisms to control access to data, including AWS Identity and Access Management (IAM), bucket policies, and Access Control Lists (ACLs).
- Versioning: Allows multiple variants of an object to be stored in the same bucket, useful for backup and recovery.
![]()

S3 is widely used in a variety of applications such as website hosting, data backup, and a backend storage for services such as Amazon EC2, Amazon EBS, and Amazon RDS.
Types of AWS S3
- S3 Standard:
Use Case: Frequently accessed data.
Characteristics: Offers high durability, availability, and performance with low latency and high throughput. - S3 Intelligent-Tiering:
Use Case: Data with unknown or changing access patterns.
Characteristics: Automatically moves data between two access tiers — frequent and infrequent access — based on changing access patterns, optimizing costs without performance impact. - S3 Standard-Infrequent Access (S3 Standard-IA):
Use Case: Less frequently accessed data, but requires rapid access when needed.
Characteristics: Lower storage cost compared to S3 Standard, but with a retrieval fee. - S3 One Zone-Infrequent Access (S3 One Zone-IA):
Use Case: For data that is infrequently accessed and does not require the multiple Availability Zone data resilience.
Characteristics: Stores data in a single Availability Zone, making it less expensive than S3 Standard-IA. - S3 Glacier:
Use Case: Archiving data that is rarely accessed.
Characteristics: Offers very low storage cost but has higher retrieval times and fees. Suitable for data archiving and long-term backup. - S3 Glacier Deep Archive:
Use Case: Long-term storage of data that is accessed once or twice a year.
Characteristics: AWS’s lowest-cost storage class and supports long-term retention and digital preservation for data that may be accessed once or twice a year.
Quick Quiz

Amazon EFS (Amazon Elastic File System)
AWS EFS is a cloud-based file storage service for applications that require shared file storage accessible by multiple EC2 instances. EFS is scalable and elastic, providing a simple interface that allows storage capacity to grow or shrink automatically as files are added or removed. It uses the NFS (Network File System) protocol and can be mounted on several instances simultaneously, making it ideal for applications that need common data access for multiple servers, such as content management systems and web serving.
- Differences between AWS EFS and AWS EBS:
- Storage Type:
EFS is a file-level storage service that operates on the NFS protocol, allowing simultaneous access from multiple EC2 instances.
EBS is a block-level storage service attached to a single EC2 instance at a time, used like a traditional drive. - Scalability:
EFS automatically scales its capacity up or down as you add or remove files, with no need for manual intervention or provisioning.
EBS requires manual management of capacity. You must choose the volume size ahead of time, though you can resize it, the process is not automatic. - Use Case:
EFS is ideal for use cases where multiple instances need to access a common file system concurrently, such as web applications and content management systems.
EBS is better suited for use cases requiring dedicated, single-instance storage, such as databases or any application needing consistent block-level storage. - Performance:
EFS offers scalable performance, but with slightly higher latency due to its network-based nature.
EBS provides high performance with lower latency, especially with provisioned IOPS volumes for I/O-intensive applications. - Data Durability and Availability:
EFS is designed to be highly durable and available, storing data across multiple Availability Zones automatically.
EBS volumes are tied to a specific Availability Zone; however, you can take snapshots and replicate them to other zones for higher availability and durability.
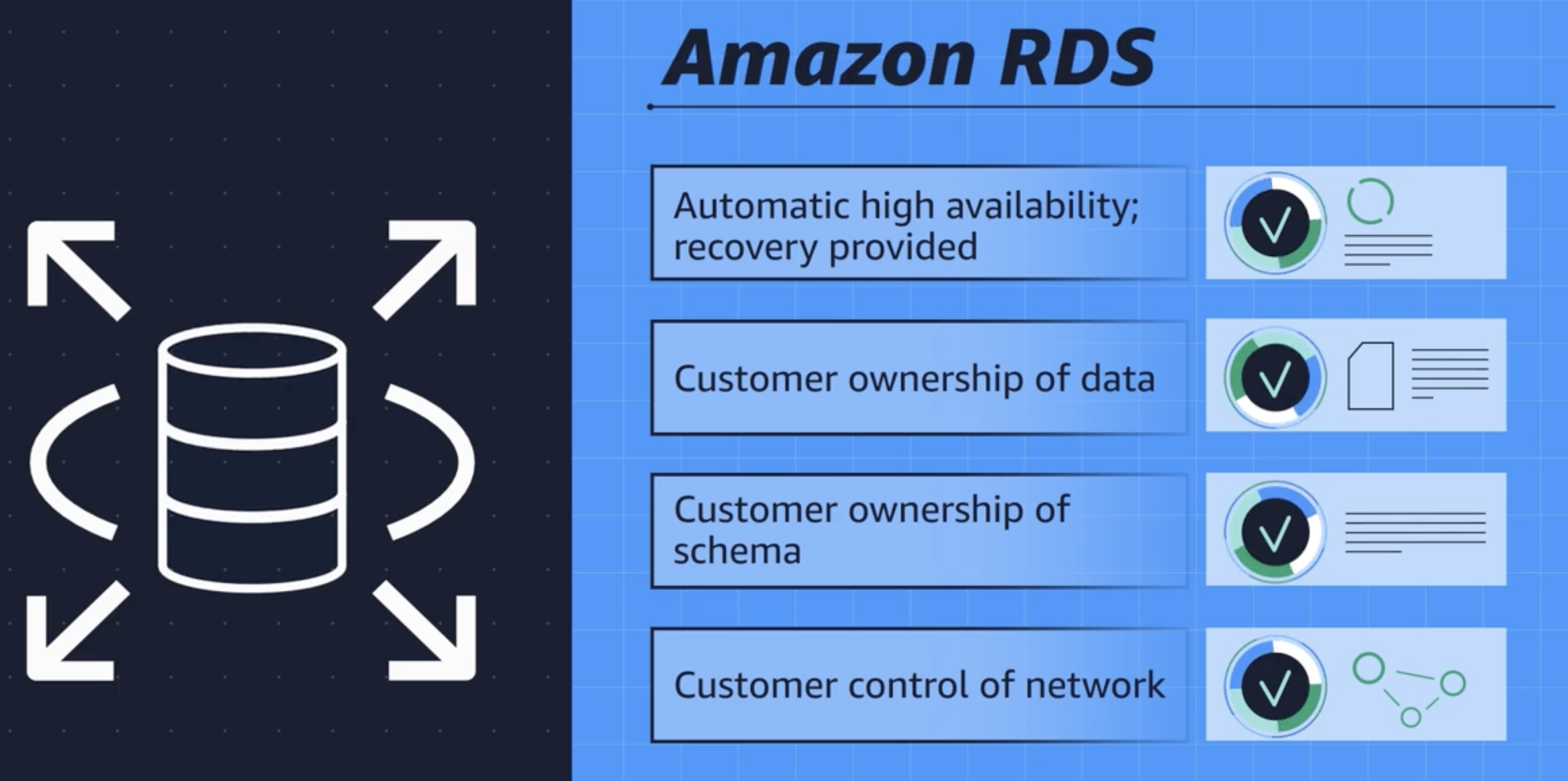
Amazon RDS (Amazon Relational Database Service)
AWS RDS is a managed relational database service that simplifies the setup, operation, and scaling of a relational database in the cloud. It provides cost-efficient and resizable capacity while automating time-consuming administration tasks such as hardware provisioning, database setup, patching, and backups. RDS allows you to focus on your applications so you can give them the fast performance, high availability, security, and compatibility they need.
Amazon RDS database engines
Amazon RDS is available on six database engines, which optimize for memory, performance, or input/output (I/O). Supported database engines include:
- Amazon Aurora
- PostgreSQL
- MySQL
- MariaDB
- Oracle Database
- Microsoft SQL Server
Amazon Aurora
Amazon Aurora is an enterprise-class relational database. It is compatible with MySQL and PostgreSQL relational databases. It is up to five times faster than standard MySQL databases and up to three times faster than standard PostgreSQL databases.
Amazon Aurora helps to reduce your database costs by reducing unnecessary input/output (I/O) operations, while ensuring that your database resources remain reliable and available.
Consider Amazon Aurora if your workloads require high availability. It replicates six copies of your data across three Availability Zones and continuously backs up your data to Amazon S3.
Amazon DynamoDB
AWS DynamoDB is a fully managed NoSQL database service that provides fast and predictable performance with seamless scalability. DynamoDB lets you offload the administrative burdens of operating and scaling a distributed database, so you do not have to worry about hardware provisioning, setup and configuration, replication, software patching, or cluster scaling.

Features
Amazon DynamoDB is a key-value database service. It delivers single-digit millisecond performance at any scale. Here are 2 important features of Amazon DynamoDB.
- Serverless
- DynamoDB is serverless, which means that you do not have to provision, patch, or manage servers.
- You also do not have to install, maintain, or operate software.
- Automatic Scaling
- As the size of your database shrinks or grows, DynamoDB automatically scales to adjust for changes in capacity while maintaining consistent performance.
- This makes it a suitable choice for use cases that require high performance while scaling.
Amazon RDS VS. Amazon DynamoDB

- Database Type
- RDS: Relational database service supporting SQL queries and complex transactions, suitable for structured data.
- DynamoDB: NoSQL database service optimized for high performance and scalability, handling key-value and document data.
- Use Cases
- RDS: Ideal for applications requiring complex queries and transactional integrity, such as business software and reporting systems.
- DynamoDB: Best for applications needing fast access, massive scalability, like mobile apps, gaming platforms, and IoT systems.
- Performance and Scalability
- RDS: Scalable vertically (upgrading server resources); performance relies on SQL optimization.
- DynamoDB: Automatically scalable horizontally, offering consistent single-digit millisecond latency at any scale.
- Management
- RDS: Requires some management for scaling and backups.
- DynamoDB: Fully managed, with automatic scaling, partitioning, and replication.
- Pricing
- RDS: Charges based on compute, storage, and additional features like backups and replication.
- DynamoDB: Pricing based on throughput, storage, and optional features like data streaming.
Conclusion: Choose RDS for complex relational databases and DynamoDB for high-performance, scalable, simple data structure needs. Each has its strengths depending on the application’s requirements.
Quick Quiz
Amazon Redshift
AWS Redshift is a fully managed, petabyte-scale data warehouse service in the cloud. It provides fast query performance by using columnar storage technology to improve I/O efficiency and parallelizing queries across multiple nodes.
What is Data Warehouse?
A Data Warehouse is a system used for reporting and data analysis, and is considered a core component of business intelligence. It is designed to enable and support business decisions by consolidating, aggregating, and organizing data from multiple sources into a central repository. This repository is structured specifically for query and analysis, often using historical data derived from transaction data, but it can include data from other sources.
Data warehouses support various data analysis tools, such as online analytical processing (OLAP) and data mining. The primary function of a data warehouse is to enable data analysis and support decision-making. It acts as a central repository where information is stored and can be retrieved from multiple sources, making it a valuable resource for gaining insight into the functioning and performance of an organization over time.
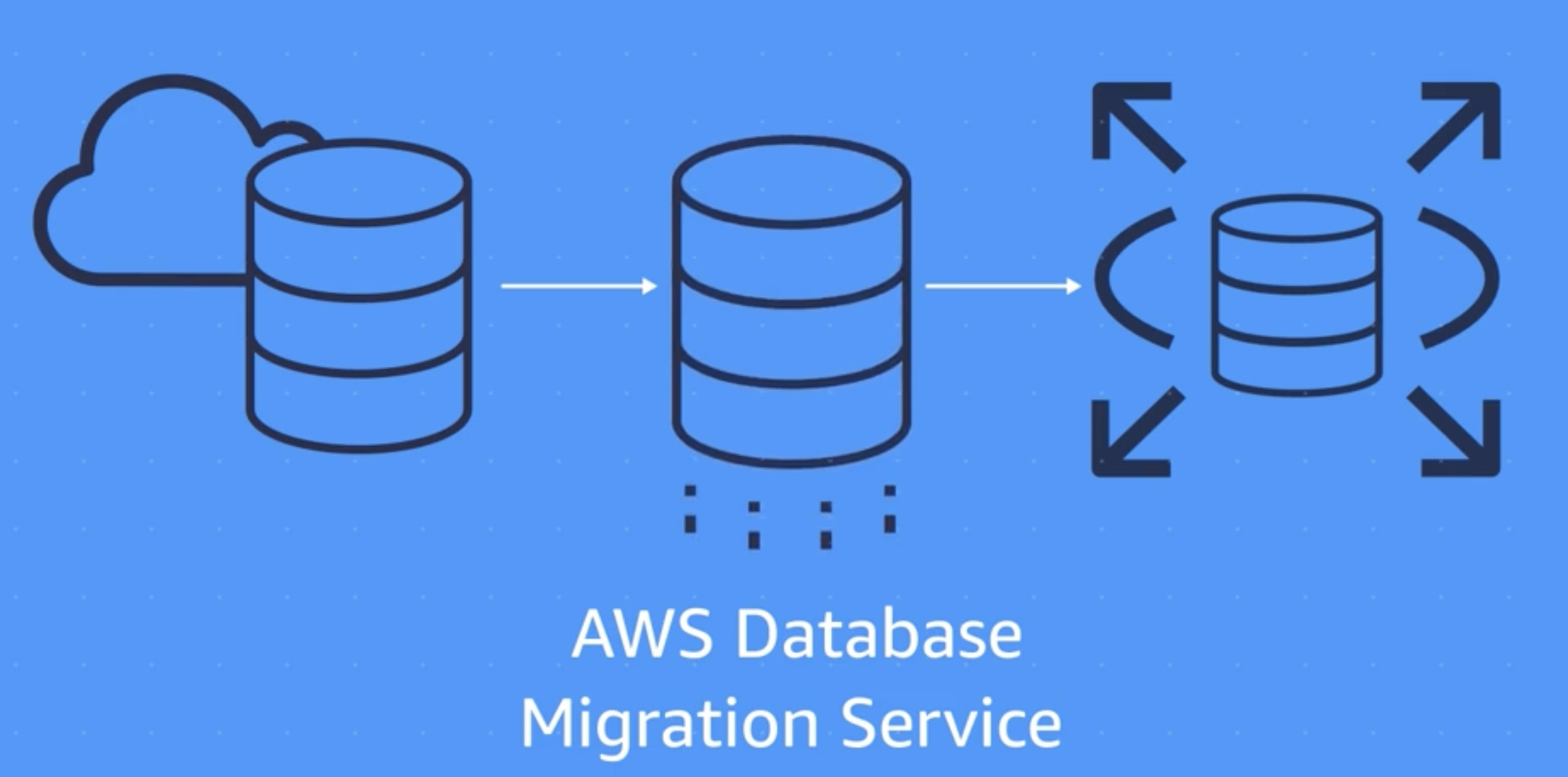
AWS DMS (AWS Database Migration Service)
AWS Database Migration Service (AWS DMS) is a cloud service that makes it easier for you to migrate relational databases, data warehouses, NoSQL databases, and other types of data stores to AWS. DMS can also be used to migrate data between on-premises databases, between different AWS cloud services, or between a combination of cloud and on-premises setups.
2 Processes (Heterogeneous Database)
AWS Schema Conversion Tool to make the schema structures and database code to match the target DB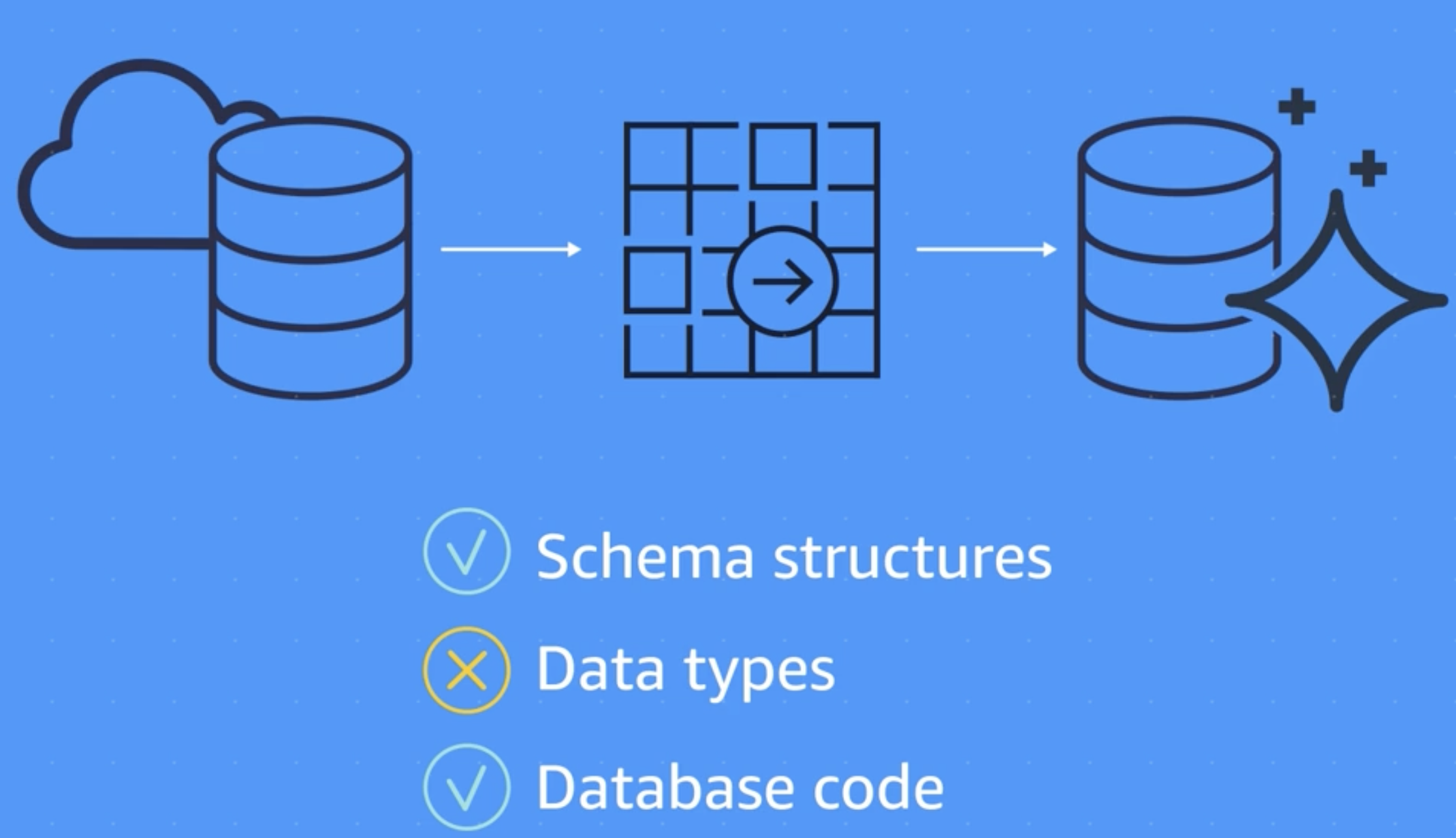
AWS DMS to migrate
Use Cases
- Development and test database migrations
- Enabling developers to test applications against production data without affecting production users
![]()
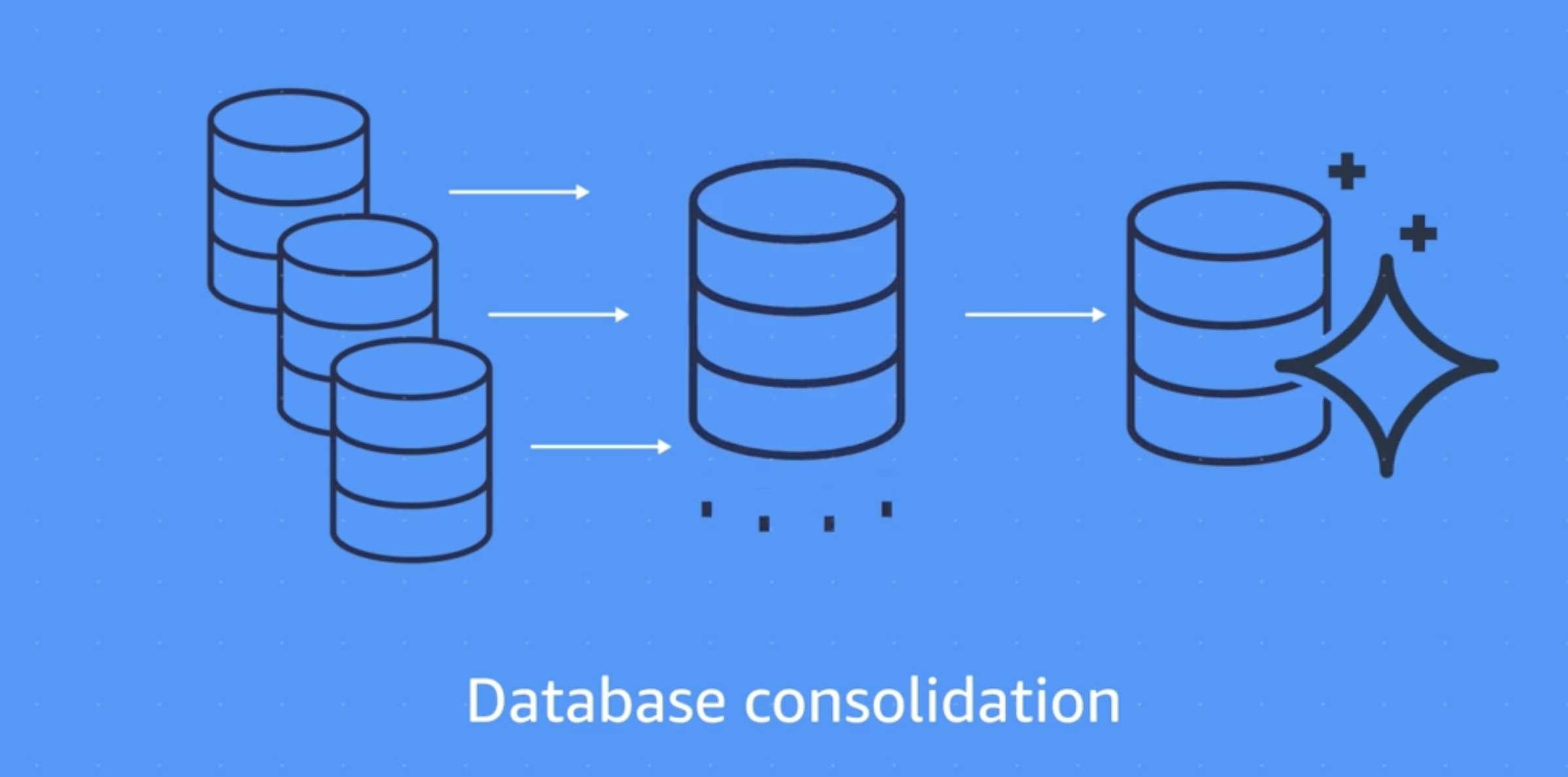
- Database consolidation
- Combining several databases into a single database
![]()
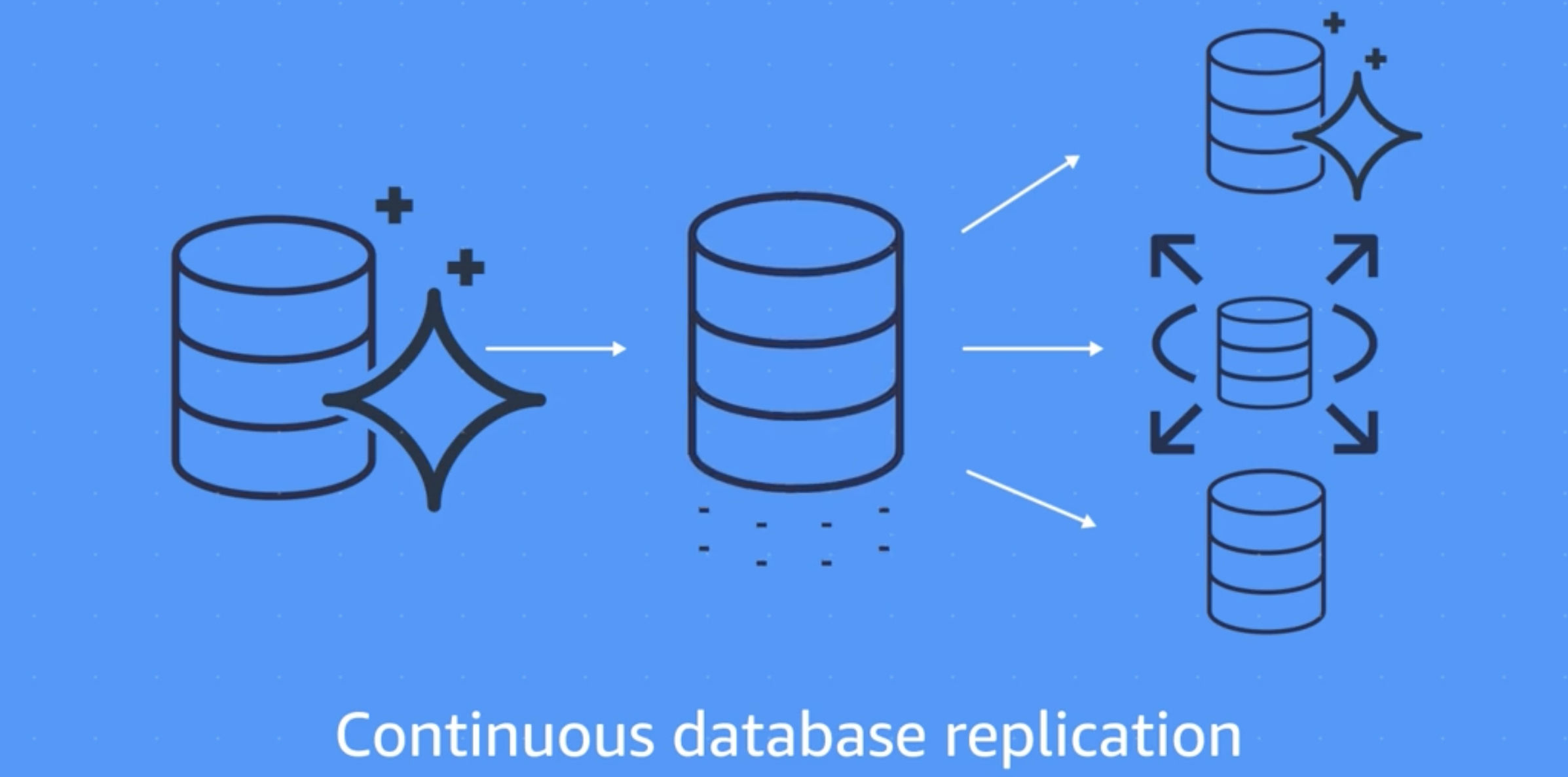
- Continuous replication
- Sending ongoing copies of your data to other target sources instead of doing a one-time migration
![]()

Additional Database Services
Selecting the appropriate database and storage solutions is crucial for meeting specific business needs without compromising on functionality. AWS offers a range of specialized database services tailored to unique business requirements.
Specialized AWS Database Services
Amazon DocumentDB
Ideal for content-heavy applications such as content management systems, catalogs, and user profiles, Amazon DocumentDB supports complex document storage needs.Amazon Neptune
Amazon Neptune is a graph database designed for managing intricate data relationships efficiently, suitable for social networks, recommendation systems, and fraud detection.Amazon Managed Blockchain and Amazon QLDB
For applications requiring immutable records, such as in supply chain or financial sectors, Amazon QLDB provides a secure, immutable ledger system, whereas Amazon Managed Blockchain introduces a decentralized blockchain solution.Performance Enhancement Options
Amazon ElastiCache
Improves database read times significantly, offering caching solutions like Memcached and Redis to enhance performance without maintenance overhead.DAX (DynamoDB Accelerator)
A native caching layer for DynamoDB, DAX boosts read performance dramatically, making it ideal for applications requiring speedy data retrieval.
Summary
- Elastic Block Store (EBS): Provides persistent block storage volumes for EC2 instances, ensuring local storage that is not ephemeral.
- Amazon S3: A robust object storage service that allows users to store and retrieve vast amounts of data easily via a user interface or API.
- Database Options: Explored relational databases available on AWS for structured data management and DynamoDB for key-value pair, non-relational workloads.
- Elastic File System (EFS): Offers a simple, scalable file storage solution for use with AWS Cloud services and on-premises resources.
- Amazon Redshift: Serves as a fully managed data warehouse that provides powerful and fast data analysis across your datasets.
- Database Migration Service (DMS): Facilitates the migration of your databases to AWS, ensuring seamless data transfer with minimal downtime.
- Specialized Storage Services: Briefly covered less commonly known services like Amazon DocumentDB, Neptune, QLDB, and Amazon Managed Blockchain for specific use cases.
- Caching Solutions: Discussed the use of Amazon ElastiCache and DynamoDB Accelerator to improve the performance of database reads.
Quiz





Reference:
- AWS SkillBuilder CPE Course Module5